Complete guide to Java Stream API in pictures and examples
31 min read February 16, 2025 #javaSince the release of Java 8, I almost immediately started using the Stream API, because I liked the functional approach of data processing. I wanted to use it everywhere, so I began developing my own library, which brings a similar approach to earlier versions of Java, specially for Android. I was also interested in the stream internals. Over time, I've accumulated enough experience, and now I'm eager to share it.
In this article, along with a description of streams, I provide visual demonstrations of how operators work, as well as examples and self-checking tasks. It also covers new features related to streams in Java 9+.
Updates
- 2025-01-15: Added Collector.teeing from Java 12 and peek optimization
- 2025-01-29: Added description of gather from Java 22
- 2021-05-08: Added descriptions of mapMulti and toList from Java 16
Self-checks
In this article, especially in the Tasks section, you'll encounter code with an input field. These are self-checking tasks.
Type OK to complete task: /*!interactive answer='OK'*/
Type random number from 0 to 99: /*!interactive answer='42'*/
If the entered answer is correct, the field will become green.
1. Stream#
A Stream is an object for universal data processing. We specify what operations we want to perform without worrying about the implementation details. For example, take elements from a list of employees, select those younger than 40, sort by last name, and place them in a new list. Or a bit more complex, read all JSON files in the books folder, deserialize them into a list of book objects, process the elements of all these lists, and then group the books by author.
Data can be obtained from sources, which are collections or methods that supply data. For example, a list of files, an array of strings, the range() method for numeric intervals, etc. That is, a stream uses existing collections to obtain new elements, it's by no means a new data structure.
The data is then processed by operators. For example, take only certain elements (filter), transform each element (map), calculate the sum of elements, or combine everything into one object (reduce).

Operators can be divided into two groups:
- Intermediate — process incoming elements and return a stream. There can be many intermediate operators in the element processing chain.
- Terminal — process elements and terminate the stream, so there can only be one terminal operator in the chain.
2. Obtaining a Stream object#
Enough theory for now. It's time to see how to create or obtain a java.util.stream.Stream object.
- Empty stream:
Stream.empty() // Stream<String> - Stream from List:
list.stream() // Stream<String> - Stream from Map:
map.entrySet().stream() // Stream<Map.Entry<String, String>> - Stream from an array:
Arrays.stream(array) // Stream<String> - Stream from specified elements:
Stream.of("a", "b", "c") // Stream<String>
Here's an example:
public static void
In this example, the source is the Arrays.stream method, which creates a stream from the args array. The intermediate operator filter selects only those strings whose length does not exceed two. The terminal operator collect gathers the resulting elements into a new list.
And another example:
IntStream.
.
.
.
.
There are three intermediate operators:
filter— selects elements with values less than 300,map— adds 11 to each number,limit— limits the number of elements to 3.
The terminal operator forEach applies the print function to each incoming element.
In earlier versions of Java, this example would look like this:
int[] arr ;
int count ;
for
As the number of operators increased, the code in earlier versions would become significantly more complex, not to mention that splitting the computation into multiple threads would be extremely difficult with this approach.
3. How Stream works#
Streams have certain characteristics. First, processing doesn't start until a terminal operator is called. list.stream().filter(x -> x > 100); will not take a single element from the list. Second, a stream cannot be reused after it has been processed.
Stream stream ;
stream.;
stream.;
stream.;
The code on the second line will execute, but the third line will throw an exception:
java.lang.IllegalStateException: stream has already been operated upon or closed
From the first characteristic we conclude that processing occurs from the terminal operator to the source. This is indeed the case, and it's convenient. We can use a generated infinite sequence, such as factorials or Fibonacci numbers as a source, but process only a part of it.
Until we attach a terminal operator, the source is not accessed. As soon as the terminal operator forEach appears, it starts requesting elements from the preceding limit operator. In turn, limit refers to map, map to filter, and filter to the source. Then the elements flow in the direct order: source, filter, map, limit, and forEach.
As long as any operator doesn't process an element properly, new ones will not be requested.
Once 3 elements have passed through the limit operator, it goes into a closed state and will no longer request elements from map. forEach requests the next element, but limit indicates that it can no longer supply elements, so forEach concludes that the elements have run out and stops working.
This approach is called pull iteration, meaning elements are requested from the source as needed. By the way, in RxJava, a push iteration approach is implemented, where the source itself notifies that elements have appeared and need to be processed.
4. Parallel Streams#
Streams can be sequential or parallel. Sequential streams are executed only in the current thread, while parallel streams use the common pool ForkJoinPool.commonPool(). In this case, the elements are split (if possible) into several groups and processed separately in each thread. Then, at the certain stage, the groups are combined into one to provide the final result.
To obtain a parallel stream, you need to either call the parallelStream() method instead of stream(), or convert a regular stream into a parallel one by calling the intermediate operator parallel.
list.
.
.
.;
IntStream.
.
.
.;
Working with thread-unsafe collections, splitting elements into parts, creating threads, combining parts, all this is hidden in the Stream API implementation. All we need to do is call the right method and ensure that the functions in the operators do not depend on any external factors, otherwise there's a risk of getting an incorrect result or an error.
Here's what you shouldn't do:
final List ints ;
IntStream.
.
.;
System.out.;
This is Schrödinger's code. It may execute normally and show 1000000, it may execute and show 869877, or it may fail with an error:
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 332 at java.util.ArrayList.add(ArrayList.java:459)
Therefore, developers strongly advise against side effects in lambdas, repeatedly mentioning non-interference in the documentation.
5. Streams for primitives#
In addition to object streams Stream<T>, there are special streams for primitive types:
IntStreamforint,LongStreamforlong,DoubleStreamfordouble.
For boolean, byte, short, and char, no special streams were created, but you can use IntStream instead and then cast to the desired type. For float, you will also have to use DoubleStream.
Primitive streams are useful because you don't need to spend time on boxing/unboxing, and they also have a number of special operators that make life easier. We will look at them very soon.
6. Stream API operators#
The following are Stream API operators with descriptions, demonstrations, and examples. You can use this as a reference.
Quick jump
Sources: empty, of, ofNullable, generate, iterate, concat, builder, range, rangeClosed
Intermediates: filter, map, flatMap, mapMulti, gather, limit, skip, sorted, distinct, peek, takeWhile, dropWhile, boxed
Terminals: forEach, forEachOrdered, count, collect, toArray, toList, reduce, min, max, findAny, findFirst, allMatch, anyMatch, noneMatch, average, sum, summaryStatistics
6.1. Sources#
empty()#
Stream, like a collection, can be empty, meaning all subsequent operators will have nothing to process.
Stream.
.;
// No output
of(T value)
of(T... values)#
Stream for one or more specified elements. I often see this construction used:
Arrays..
.;
However, it's redundant. This is simpler:
Stream.
.;
ofNullable(T t)#
Introduced in Java 9. Returns an empty stream if null is passed as an argument, otherwise returns a stream of one element.
String str ;
Stream.
.;
generate(Supplier s)#
Returns a stream with an infinite sequence of elements generated by the Supplier function s.
Stream.
.
.;
// 6, 6, 6, 6, 6, 6
Since the stream is infinite, it needs to be limited or used carefully to avoid an infinite loop.
iterate(T seed, UnaryOperator f)#
Returns an infinite stream with elements generated by sequentially applying the function f to the iterated value. The first element will be seed, then f(seed), then f(f(seed)), and so on.
Stream.
.
.;
// 2, 8, 14, 20, 26, 32
Stream.
.
.;
// 1, 2, !interactive answer='4', !interactive answer='8', !interactive answer='16', 32
iterate(T seed, Predicate hasNext, UnaryOperator f)#
Introduced in Java 9. It is the same as the previous method, but with an additional argument hasNext: if it returns false, the stream terminates. This is very similar to a for loop:
for
Thus, with iterate you can now create a finite stream.
Stream.
.;
// 2, 8, 14, 20
Stream.
.;
// !interactive answer='4', 16, !interactive answer='64'
concat(Stream a, Stream b)#
Combines two streams so that the elements of stream A come first, followed by the elements of stream B.
Stream.
.;
// 1, 2, 3, 4, 5, 6
Stream.
.;
// 10, 4, 16
builder()#
Creates a mutable object for adding elements to a stream without using any container for this purpose.
Stream.Builder streamBuider ;
for
streamBuider
.
.
.
.;
// 0, 1, 2, 4, 6, 8, 9, 10
IntStream.range(int startInclusive, int endExclusive)
LongStream.range(long startInclusive, long endExclusive)#
Creates a stream from the numerical range [start..end), i.e., from start (inclusive) to end (exclusive).
IntStream.
.;
// 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
LongStream.
.;
// -10, -9, -8, -7, -6
IntStream.rangeClosed(int startInclusive, int endInclusive)
LongStream.rangeClosed(long startInclusive, long endInclusive)#
Creates a stream from the numerical range [start..end], i.e., from start (inclusive) to end (inclusive).
IntStream.
.;
// 0, 1, 2, 3, 4, 5
LongStream.
.;
// -8, -7, -6, -5
6.2. Intermediate operators#
filter(Predicate predicate)#
Filters the stream, accepting only those elements that satisfy the given condition.
Stream.
.
.;
// No output, because the stream will become empty after filtering
Stream.
.
.;
// 120, 410, 314
IntStream.
.
.;
// 3, 6
map(Function mapper)#
Applies a function to each element and then returns a stream where the elements are the results of the function. map can be used to change the type of elements.
Stream.mapToDouble(ToDoubleFunction mapper)
Stream.mapToInt(ToIntFunction mapper)
Stream.mapToLong(ToLongFunction mapper)
IntStream.mapToObj(IntFunction mapper)
IntStream.mapToLong(IntToLongFunction mapper)
IntStream.mapToDouble(IntToDoubleFunction mapper)
Special operators for converting an object stream to a primitive stream, a primitive stream to an object stream, or a primitive stream of one type to a primitive stream of another type.
Stream.
.
.
.;
// 13, 14, 15
Stream.
.
.;
// 131, 421, 96, 43, 325, 23
Stream.
.
.;
// !interactive answer='16', !interactive answer='17', 50
flatMap(Function<T, Stream<R>> mapper)#
One of the most interesting operators. Works like map, but with one difference — you can transform one element into zero, one, or multiple others.
flatMapToDouble(Function mapper)
flatMapToInt(Function mapper)
flatMapToLong(Function mapper)
Like map, these are used to convert to a primitive stream.
To transform one element into zero elements, you need to return null or an empty stream. To transform into one element, you need to return a stream of one element, for example, via Stream.of(x). To transform into multiple elements, you can create a stream with those elements in any way.
Stream.
.
.;
// 0, 1, 0, 1, 2, 0, 0, 1, 2
Stream.
.
.;
// 1, 3, 9, 18, 4, 6, 36, 72
mapMulti(BiConsumer<T, Consumer<R>> mapper)#
Introduced in Java 16. This operator is similar to flatMap but uses an imperative approach. Now, along with the stream element, a Consumer is also provided, into which you can pass one or more values, or none at all.
Here's how it was with flatMap:
Stream.
.
.;
// -2, 2, -4, 4, -6, 6
And here is how you can rewrite it using mapMulti:
Stream.
.
.;
// -2, 2, -4, 4, -6, 6
mapMultiToDouble(BiConsumer<T, DoubleConsumer> mapper)
mapMultiToInt(BiConsumer<T, IntConsumer> mapper)
mapMultiToLong(BiConsumer<T, LongConsumer> mapper)
Used for converting to a primitive stream.
mapMulti has several advantages over flatMap. First, if you need to skip values (as in the example above, where odd elements were skipped), there will be no overhead for creating an empty stream. Second, the consumer can easily be passed to another method where transformations, including recursive ones, can be performed.
void
Serializable
Stream.
.
.;
// A, B, C, D, E, F, G
gather(Gatherer<T, R> gatherer)#
Introduced in Java 22. gather allows you to create your own intermediate operators. To do this, you need to create a Gatherer object, in which you specify the processing logic. For example:
public <T> Gatherer
Stream...
// A, A, B, B, C, C, D, D
The Gatherers class already has several useful predefined operators:
IntStream.
.
.
.;
// [1, 2, 3]
// [4, 5, 6]
// [7, 8, 9]
// [10]
IntStream.
.
.
.;
// [1, 2, 3, 4, 5]
// [2, 3, 4, 5, 6]
// [3, 4, 5, 6, 7]
// [4, 5, 6, 7, 8]
// [5, 6, 7, 8, 9]
// [6, 7, 8, 9, 10]
limit(long maxSize)#
Limits the stream to maxSize elements.
Stream.
.
.;
// 120, 410, 85, 32
Stream.
.
.
.;
// 120, 410
Stream.
.
.;
// No output
skip(long n)#
Skips n elements of the stream.
Stream.
.
.;
// No output
Stream.
.
.;
// 85, 32, 314, 12
IntStream.
.
.
.;
// !interactive answer='3', !interactive answer='4'
IntStream.
.
.
.
.;
// !interactive answer='6', !interactive answer='7'
sorted()
sorted(Comparator comparator)#
Sorts the elements of the stream. This operator works cleverly: if the stream is already marked as sorted, sorting will not be performed. Otherwise, it collects all elements, sorts them, and returns a new stream marked as sorted. See 9.1.
IntStream.
.
.
.;
// 0, 1, 2
IntStream.
.
.
.;
// Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
Stream.
.
.;
// 12, 32, 85, 120, 314, 410
Stream.
.
.;
// 410, 314, 120, 85, 32, 12
distinct()#
Removes duplicate elements and returns a stream with unique elements. Like sorted, it checks if the stream already consists of unique elements and, if not, selects unique elements and marks the stream as containing unique elements.
Stream.
.
.;
// 2, 1, 8, 3
IntStream.
.
.;
// !interactive answer='2', !interactive answer='3', !interactive answer='4', !interactive answer='0', !interactive answer='1'
peek(Consumer action)#
Performs an action on each element of the stream and returns a stream with the elements of the original stream. It's used to pass an element somewhere without breaking the chain of operators (remember that forEach is a terminal operator and the stream terminates after it), or for debugging.
Stream.
.
.
.
.
.;
// before distinct: 0
// after distinct: 0
// after map: 0
// before distinct: 3
// after distinct: 3
// after map: 9
// before distinct: 1
// after distinct: 1
// after map: 1
// before distinct: 5
// before distinct: 0
// before distinct: 5
// after distinct: 5
// after map: 25
takeWhile(Predicate predicate)#
Introduced in Java 9. Returns elements as long as they satisfy the condition, i.e., the predicate function returns true. This is similar to limit, but with a condition instead of a number.
Stream.
.
.;
// 1, 2
IntStream.
.
.;
// 2, 3, 4
dropWhile(Predicate predicate)#
Introduced in Java 9. Skips elements as long as they satisfy the condition, then returns the remaining part of the stream. If the predicate returns false for the first element, no elements will be skipped. This operator is similar to skip, but works based on a condition.
Stream.
.
.;
// 1, 2, 3, 4, 2, 5
Stream.
.
.;
// 3, 4, 2, 5
IntStream.
.
.;
// 5, 6
IntStream.
.
.;
// 2, 0, 5, 6
boxed()#
Converts a primitive stream to an object stream.
DoubleStream.
.
.
.;
// class java.lang.Double
// class java.lang.Double
6.3. Terminal operators#
void forEach(Consumer action)#
Performs the specified action for each element of the stream.
Stream.
.;
// 120, 410, 85, 32, 314, 12
void forEachOrdered(Consumer action)#
Also performs the specified action for each element of the stream, but ensures the correct order of elements before doing so. Useful for parallel streams when the correct sequence of elements is needed.
IntStream.
.
.
.
.;
// 5, 6, 7, 3, 4, 8, 0, 9, 1, 2
IntStream.
.
.
.
.;
// 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
long count()#
Returns the number of elements in the stream.
long count ;
System.out.;
// 45
System.out.;
// 10
System.out.;
// 0
Warning! peek optimization
If this operator doesn't make any changes to the stream, it may be automatically excluded from the pipeline for the optimization sake.
long count ;
System.out.;
In this example peek doesn't affect the stream elements count, thus it'll be skipped and only the result 10 will be printed.
R collect(Collector collector)#
One of the most powerful Stream API operators. It allows you to collect all elements into a list, set, or another collection, group elements by some criterion, combine everything into a string, etc. The java.util.stream.Collectors class has many methods for various use cases, which we will explore later. If desired, you can write your own collector by implementing the Collector interface.
List list ;
// list: [1, 2, 3]
String s ;
// s: "<1-2-3>"
R collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner)#
The same as collect(collector), but with parameters broken down for convenience. If you need to quickly perform some operation, there is no need to implement the Collector interface; just pass three lambda expressions.
The supplier should provide new objects (containers), for example, new ArrayList().
The accumulator adds an element to the container.
The combiner is necessary for parallel streams and combines parts of the stream into one.
List list ;
// list: ["a", "b", "c", "d"]
Object[] toArray()#
Returns a non-typed array with the elements of the stream.
A[] toArray(IntFunction<A[]> generator)
Similarly, returns a typed array.
String[] elements ;
// elements: ["a", "b", "c", "d"]
List<T> toList()#
Finally added in Java 16. Returns a list, similar to collect(Collectors.toList()). The difference is that the returned list is guaranteed to be unmodifiable. Any addition or removal of elements in the resulting list will result in an UnsupportedOperationException.
List elements ;
// elements: ["A", "B", "C", "D"]
T reduce(T identity, BinaryOperator accumulator)
U reduce(U identity, BiFunction accumulator, BinaryOperator combiner)#
Another useful operator. Allows you to transform all elements of the stream into one object. For example, calculate the sum of all elements or find the minimum element.
First, the identity object and the first element of the stream are taken, the accumulator function is applied, and identity becomes its result. Then the process continues for the remaining elements.
int sum ;
// sum: 25
Optional reduce(BinaryOperator accumulator)#
This method differs in that it does not have an initial identity object. The first element of the stream serves as the identity. Since the stream can be empty and the identity object will not be assigned, the result of the function is an Optional, allowing you to handle this situation by returning Optional.empty().
Optional result ;
System.out.;
// false
Optional sum ;
System.out.;
// 15
int sum ;
// sum: 25
int product ;
// product: !interactive answer='0'
Optional min(Comparator comparator)#
Optional max(Comparator comparator)#
Finds the minimum/maximum element based on the provided comparator. Internally, reduce is called:
);
);
int min ;
// min: 11
int max ;
// max: 78
Optional findAny()#
Returns the first encountered element of the stream. In parallel streams, this can be any element that was in the split part of the sequence.
Optional findFirst()#
Guaranteed to return the first element of the stream, even if the stream is parallel.
If any element is needed, findAny() will work faster for parallel streams.
int anySeq ;
// anySeq: 4
int firstSeq ;
// firstSeq: 4
int anyParallel ;
// anyParallel: 32770
int firstParallel ;
// firstParallel: 4
boolean allMatch(Predicate predicate)#
Returns true if all elements of the stream satisfy the predicate condition. If any element is found for which the predicate function returns false, the operator stops looking at the elements and returns false.
boolean result ;
// result: true
boolean result ;
// result: false
boolean result ;
// result: !interactive size='4' answer='false'
boolean anyMatch(Predicate predicate)#
Returns true if at least one element of the stream satisfies the predicate condition. If such an element is found, there is no need to continue iterating through the elements, so the result is returned immediately.
boolean result ;
// result: true
boolean result ;
// result: false
boolean result ;
// result: !interactive size='4' answer='false'
boolean noneMatch(Predicate predicate)#
Returns true if, after iterating through all elements of the stream, none satisfy the predicate condition. If any element is found for which the predicate function returns true, the operator stops iterating through the elements and returns false.
boolean result ;
// result: true
boolean result ;
// result: false
boolean result ;
// result: !interactive size='4' answer='true'
OptionalDouble average()#
Only for primitive streams. Returns the arithmetic mean of all elements. Or Optional.empty if the stream is empty.
double result ;
// result: 8.5
sum()#
Returns the sum of the elements of a primitive stream. For IntStream, the result will be of type int, for LongStream — long; for DoubleStream — double.
long result ;
// result: 119
IntSummaryStatistics summaryStatistics()#
A useful method for primitive streams. Allows you to collect statistics about the numeric sequence of the stream, namely: the number of elements, their sum, arithmetic mean, minimum and maximum element.
LongSummaryStatistics stats ;
System.out.;
System.out.;
System.out.;
System.out.;
System.out.;
// count: 14
// sum: 119
// average: 8,5
// min: 2
// max: 15
7. Collectors#
7.1. Collectors methods#
toList()#
The most common method. Collects elements into a List.
toSet()#
Collects elements into a Set.
toCollection(Supplier collectionFactory)#
Collects elements into the specified collection. If you need to specify exactly which List, Set, or other collection to use, this method will help.
Deque deque ;
Set set ;
toMap(Function keyMapper, Function valueMapper)#
Collects elements into a Map. Each element is transformed into a key and a value based on the results of the keyMapper and valueMapper functions, respectively. If you need to return the same element that came in, you can pass Function.identity().
Map map1 ;
// {1=1, 2=2, 3=3, 4=4, 5=5}
Map map2 ;
// {1="1 * 2 = 2", 2="2 * 2 = 4", 3="3 * 2 = 6"}
Map map3 ;
// {'2'="<50>", '6'="<54>", '7'="<55>"}
toMap(Function keyMapper, Function valueMapper, BinaryOperator mergeFunction)#
Similar to the first version of the method, but in the case where two identical keys are encountered, it allows merging the values.
Map map4 ;
// {0="<50>, <55>, <20>", 2="<52>", 4="<64>, <19>"}
In this case, for the numbers 50, 55, and 20, the key is the same and equals 0, so the values accumulate. Similarly for 64 and 19.
toMap(Function keyMapper, Function valueMapper, BinaryOperator mergeFunction, Supplier mapFactory)#
The same as above, but allows specifying exactly which Map class to use.
Map map5 ;
// {0=<50>, <55>, <20>, 4=<69>, <19>, 2=<52>}
The difference between this example and the previous one is that now the order is preserved, thanks to LinkedHashList.
toConcurrentMap(Function keyMapper, Function valueMapper)
toConcurrentMap(Function keyMapper, Function valueMapper, BinaryOperator mergeFunction)
toConcurrentMap(Function keyMapper, Function valueMapper, BinaryOperator mergeFunction, Supplier mapFactory)#
The same as toMap, but works with ConcurrentMap.
collectingAndThen(Collector downstream, Function finisher)#
Collects elements using the specified collector and then applies a function to the result.
List list ;
System.out.;
// class java.util.Collections$UnmodifiableRandomAccessList
List list2 ;
list2.;
// a=aa
// b=bb
// c=cc
// d=dd
joining()
joining(CharSequence delimiter)
joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix)#
Collects elements that implement the CharSequence interface into a single string. Additionally, you can specify a delimiter, as well as a prefix and suffix for the entire sequence.
String s1 ;
System.out.;
// abcd
String s2 ;
System.out.;
// a-b-c-d
String s3 ;
System.out.;
// [ a -> b -> c -> d ]
summingInt(ToIntFunction mapper)#
summingLong(ToLongFunction mapper)#
summingDouble(ToDoubleFunction mapper)#
A collector that converts objects to int/long/double and calculates the sum.
averagingInt(ToIntFunction mapper)#
averagingLong(ToLongFunction mapper)#
averagingDouble(ToDoubleFunction mapper)#
Similarly, but calculates the average value.
summarizingInt(ToIntFunction mapper)#
summarizingLong(ToLongFunction mapper)#
summarizingDouble(ToDoubleFunction mapper)#
Similarly, but with full statistics.
Integer sum ;
System.out.;
// 10
Double average ;
System.out.;
// 2.5
DoubleSummaryStatistics stats ;
System.out.;
// DoubleSummaryStatistics{count=4, sum=10.620000, min=1.100000, average=2.655000, max=4.040000}
All these methods and a few subsequent ones are often used as composite collectors for grouping or collectingAndThen. In the form shown in the examples, they are rarely used. I just show an example of what they return to make it clearer.
counting()#
Counts the number of elements.
Long count ;
System.out.;
// 4
filtering(Predicate predicate, Collector downstream)#
mapping(Function mapper, Collector downstream)#
flatMapping(Function downstream)#
reducing(BinaryOperator op)
reducing(T identity, BinaryOperator op)
reducing(U identity, Function mapper, BinaryOperator op)#
A special group of collectors that apply the filter, map, flatMap, and reduce operations. filtering and flatMapping were introduced in Java 9.
List ints ;
// 2, 4, 6
String s1 ;
// 2-4-6
String s2 ;
// 0, 1, 0, 0, 1, 2, 0, 1
int value ;
// 21
String s3 ;
// 123456
minBy(Comparator comparator)#
maxBy(Comparator comparator)#
Finds the minimum/maximum element based on the given comparator.
Optional min ;
min.;
// c
Optional max ;
max.;
// defgh
groupingBy(Function classifier)
groupingBy(Function classifier, Collector downstream)
groupingBy(Function classifier, Supplier mapFactory, Collector downstream)#
Groups elements by a criterion, storing the result in a Map. Together with the aggregating collectors presented above, it allows to flexibly collect data. More about combining in the Examples section.
groupingByConcurrent(Function classifier)
groupingByConcurrent(Function classifier, Collector downstream)
groupingByConcurrent(Function classifier, Supplier mapFactory, Collector downstream)#
A similar set of methods, but stores data in a ConcurrentMap.
Map map1 ;
map1..;
// 1=[c, l]
// 2=[ab, gh]
// 3=[def, ijk]
// 4=[mnop]
Map map2 ;
map2..;
// 1=CL
// 2=ABGH
// 3=DEFIJK
// 4=MNOP
Map map3 ;
map3..;
// 2=[AB, GH]
// 1=[C, L]
// 3=[DEF, IJK]
// 4=[MNOP]
partitioningBy(Predicate predicate)
partitioningBy(Predicate predicate, Collector downstream)#
Another interesting method. Splits a sequence of elements based on some criterion. Elements that satisfy the given condition go into one part, and rest go into the other.
Map map1 ;
map1..;
// false=[def, ijk, mnop]
// true=[ab, c, gh, l]
Map map2 ;
map2..;
// false=DEFIJKMNOP
// true=ABCGHL
teeing(Collector downstream1, Collector downstream2, BiFunction merger)#
Introduced in Java 12. If you're familliar with the Unix tee command, you may have already guessed what this collector does. It collects elements into two different collectors downstream1 and downstream2, and then merges the result in the merger function.
String result ;
System.out.;
// From the 7 elements, only 4 were filtered: [ab, c, gh, l]
record
Range range ;
System.out.;
Range[min, max8. Collector#
The java.util.stream.Collector interface is used to collect stream elements into a mutable container. It consists of the following methods:
Supplier<A> supplier()— a function that creates container instances.BiConsumer<A,T> accumulator()— a function that adds a new element to the container.BinaryOperator<A> combiner()— a function that combines two containers into one. In parallel streams, each part can be collected into a separate container instance, and eventually, they need to be combined into one resulting container.Function<A,R> finisher()— a function that transforms the entire container into the final result. For example, you can wrap aListinCollections.unmodifiableList.Set<Characteristics> characteristics()— returns the characteristics of the collector so that the internal implementation knows what it is dealing with. For example, you can specify that the collector supports multithreading.
Characteristics:
CONCURRENT— the collector supports multithreading, meaning separate parts of the stream can be successfully placed in the container from another thread.UNORDERED— the collector doesn't depend on the order of incoming elements.IDENTITY_FINISH— thefinish()function has a standard implementation (Function.identity()), meaning it doesn't need to be called.
8.1. Implementing a custom collector#
Before implementing a collector, make sure that the task can't be solved using a combination of standard collectors.
For example, if you need to collect only unique elements into a list, you can first collect the elements into a LinkedHashSet to preserve the order, and then add all elements to an ArrayList. The combination of collectingAndThen with toCollection and a function that passes the obtained Set to the ArrayList constructor does what's intended:
Stream.
.;
// 1 2 3 9 5 4 8
However, if the task is to collect unique elements into one part and duplicate elements into another, for example, in a Map<Boolean, List>, then using partitioningBy will not be very elegant:
final Set elements ;
Stream.
.
.;
Here you have to create a Set and use it in the collector predicate, which is undesirable. You can turn the lambda into an anonymous function, but that's even worse:
There are two ways to create your own collector:
- Create a class that implements the
Collectorinterface. - Use the
Collector.offactory.
If you want to use generics, then in the second option you can create a static function and use Collector.of inside.
Here's the resulting collector:
public static <T> Collector
Let's break it down.
The Collector interface is declared as:
T: the type of input elements.A: the type of container into which the elements will be placed.R: the type of the result.
The signature of the method returning the collector is:
public static <T> Collector
It accepts elements of type T and returns a Map<Boolean, List<T>>, similar to partitioningBy. The question mark (wildcard) in the middle parameter indicates that the internal implementation type is not important for the public API. Many methods in the Collectors class contain a wildcard as the container type.
return Collector.of
Here, the type of the container had to be specified. Since Java doesn't have a Pair or Tuple class, two different types can be placed in a Map.Entry.
// supplier
The container will be AbstractMap.SimpleImmutableEntry. The key will contain the list of duplicate elements, and the value will contain the set of unique elements.
// accumulator
Here, if an element cannot be added to the set (because it already exists there), it's added to the list of duplicate elements.
// combiner
We need to combine two Map.Entry objects. The lists of duplicate elements can be combined easily, but with unique elements it's not that simple — you need to go through each element and repeat everything that was done in the accumulator function.
By the way, the accumulator lambda can be assigned to a variable, and then the loop can be turned into c2.getValue().forEach(e -> accumulator.accept(c1, e));.
// finisher
Finally, return the result. Unique elements will be in map.get(Boolean.TRUE), and duplicate elements in map.get(Boolean.FALSE).
Map map;
map ;
// {false=[1, 2, 3, 2], true=[1, 2, 3, 9, 5, 4, 8]}
A good practice is to create collectors that accept another collector and depend on it. For example, you can collect elements not only into a List but also into any other collection (Collectors.toCollection), or into a string (Collectors.joining).
public static <T, D, A> Collector
The algorithm remains the same, but now you can't immediately collect unique elements into the second container, you have to create a new set. For convenience, a Holder class is also added, which stores two containers for unique and duplicate elements, as well as the set itself.
All operations now need to be performed through the passed collector, called downstream. It will provide a container of the required type (downstream.supplier().get()), add an element to this container (downstream.accumulator().accept(container, element)), combine containers and create the final result.
Stream.
.
.
.;
// repetitive: 1-2-3-2
// unique: 1-2-3-9-5-4-8
By the way, the first implementation of the method can now be replaced with:
public static <T> Collector
9. Spliterator#
It's time to dig a little deeper into the Stream API. Stream elements not only need to be iterated, but also split into parts and sent to other threads. Spliterator is responsible for iterating and splitting. It even sounds like Iterator, but with the prefix "Split".
Interface methods:
trySplit— as the name suggests, it tries to split the elements into two parts. If this cannot be done, or if there are not enough elements to split, it returnsnull. Otherwise, it returns anotherSpliteratorwith a part of the data.tryAdvance(Consumer action)— if there are elements for which an action can be applied, the action is performed and returnstrue. Otherwise, it returnsfalse, and the action is not performed.estimateSize()— returns an approximate number of elements remaining for processing, orLong.MAX_VALUEif the stream is infinite or the size cannot be determined.characteristics()— returns the characteristics of the spliterator.
9.1. Characteristics#
In the sorted and distinct methods, it was mentioned that if a stream is marked as sorted or containing unique elements, the corresponding operations will not be performed. The characteristics of the spliterator influence this behavior.
DISTINCT— all elements are unique. Spliterators of allSetimplementations contain this characteristic.SORTED— all elements are sorted.ORDERED— the order matters. Spliterators of most collections contain this characteristic, butHashSet, for example, doesn't.SIZED— the number of elements is known exactly.SUBSIZED— the number of elements in each partitioned part is known exactly.NONNULL—nulldoesn't appear in elements. Some collections fromjava.util.concurrent, which don't allownullvalues, contain this characteristic.IMMUTABLE— the source is immutable, and no elements can be added or removed from it.CONCURRENT— the source is loyal to any modifications.
Of course, characteristics can be changed when executing a chain of operators. For example, the SORTED characteristic is added after the sorted operator, the SIZED characteristic is removed after the filter, etc.
9.2. Spliterator lifecycle#
To understand when and how a spliterator calls a particular method, let's create a wrapper that logs all calls. To create a stream from a spliterator, the StreamSupport class is used.
long count ;
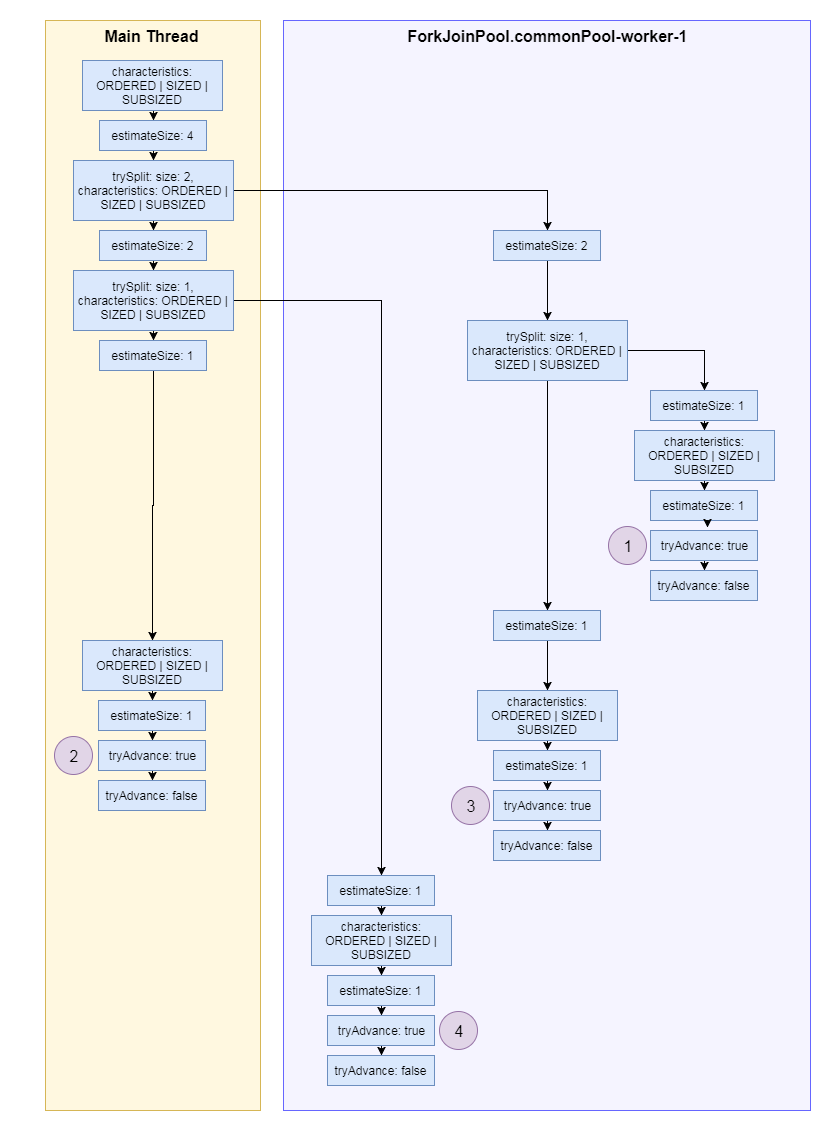
The figure shows one possible way a spliterator works. The characteristics method returns ORDERED | SIZED | SUBSIZED characteristics everywhere, as the order matters in a List, and the number of elements and all split parts are also known. The trySplit method divides the sequence in half, but not every part is necessarily sent to a new thread. In a parallel stream, a new thread might not be created because everything is processed in the main thread. But in this case, the new thread managed to process the parts before the main thread did.
Spliterator s ;
long count ;
Here the spliterator has the characteristics SIZED | DISTINCT, but for each part the SIZED characteristic is lost, leaving only DISTINCT, because it's not possible to split a set so that the size of each part is known.
In the case of a Set, there were three calls to trySplit. The first one supposedly divided the elements equally. After two others, each of the parts returned estimateSize: 1. However, in all but one case, the attempt to call tryAdvance was unsuccessful, as it returned false. But on one of the portions, which also returned an estimateSize of 1, there were four successful calls to tryAdvance. This confirms that estimateSize doesn't necessarily have to return the actual number of elements.
Arrays.;
Stream..;
The situation is similar to the List example, but the characteristics returned ORDERED | SIZED | SUBSIZED | IMMUTABLE.
Stream...;
Here, trySplit returned null, meaning it wasn't possible to split the sequence. The call hierarchy:
[main] characteristics: ORDERED | DISTINCT
[main] estimateSize: 4
[main] trySplit: null
[main] characteristics: ORDERED | DISTINCT
[main] tryAdvance: true
[main] tryAdvance: true
[main] tryAdvance: true
[main] tryAdvance: true
[main] tryAdvance: false
count: 4
Stream.
.
.
.;
Everything is the same as above, but now, after applying the map operator, the DISTINCT flag has disappeared.
9.3. Implementing a spliterator#
To correctly implement a spliterator, you need to think about how to split the elements and define the characteristics of the stream. Let's write a spliterator that generates a Fibonacci sequence.
To simplify the task, we will know the maximum number of elements to generate. This means we can split the sequence in half and then quickly calculate the required numbers based on the new index.
We only need to determine the characteristics. We have already assumed that the size of the sequence will be known, so the size of each split part will also be known. The order will matter, so the ORDERED flag is necessary. The Fibonacci sequence is also sorted, as each subsequent element is always greater than or equal to the previous one.
But with the DISTINCT flag, it seems we have a problem. The sequence 0 1 1 2 3 has repeating 1, so we can't have this flag, right? Well, nothing prevents us from calculating the flags automatically. If a part of the sequence doesn't affect the initial indices, this flag can be set:
int distinct ;
return ORDERED | distinct | SIZED | SUBSIZED | IMMUTABLE | NONNULL;
Full class implementation:
;
;
;
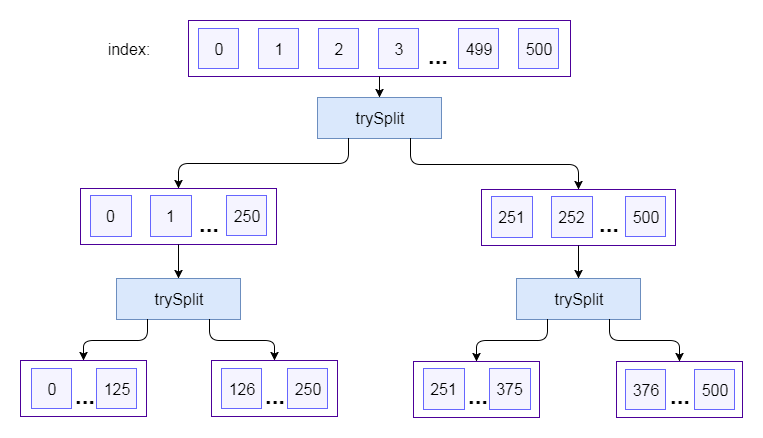
Here's how the elements of a parallel stream are now split:
StreamSupport.
.;
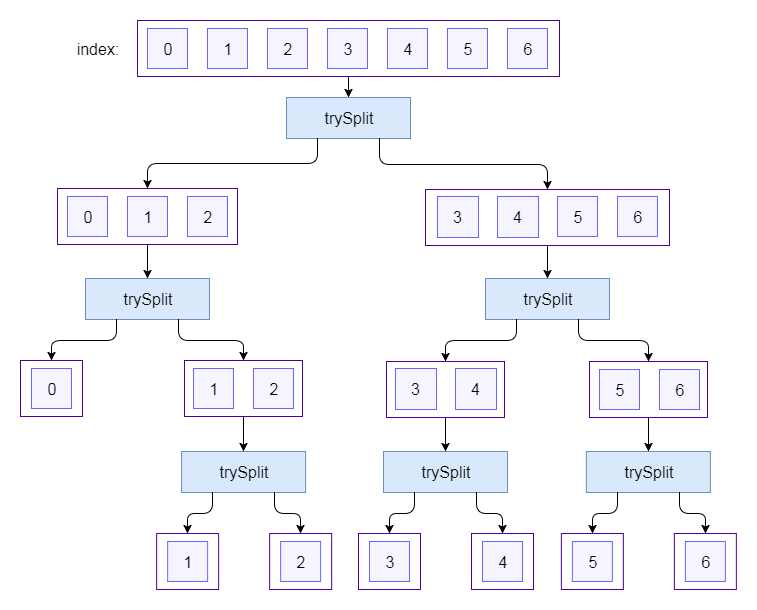
StreamSupport.
.;
10. Other ways to create sources#
Creating a stream from a spliterator is the most efficient way to create a stream, but there are other methods as well.
10.1. Stream from an iterator#
By using the Spliterators class, you can convert any iterator into a spliterator. Here's an example of creating a stream from an iterator that generates an infinite Fibonacci sequence.
StreamSupport.
.
.;
10.2. Stream.iterate + map#
You can use two operators: iterate and map, to create the same Fibonacci sequence.
Stream.
.
.
.;
For convenience, you can wrap everything in a method and call fibonacciStream().limit(10).forEach(...).
10.3. IntStream.range + map#
Another flexible and convenient way to create a stream. If you have data that can be accessed by index, you can create a numeric range using the range operator and then use map or mapToObj to access the data element by element.
IntStream.
.
.;
JSONArray arr ;
11. Examples#
Before moving on to more real-life examples, it's worth mentioning that if the code is already written without streams and works well, there's no need to hastily rewrite everything. There're also situations where it's not possible to implement a task elegantly using the Stream API. In such cases, accept it and don't force streams where they don't fit.
Given an array of arguments, we need to create a Map where each key corresponds to its value.
String[] arguments ;
Map argsMap ;
for
argsMap.;
// -i: in.txt
// --limit: 40
// -d: 1
// -o: out.txt
Quick and clear. But for the reverse task, converting a Map of arguments into an array of strings, streams will help:
String[] args ;
System.out.;
// -i in.txt --limit 40 -d 1 -o out.txt
Given a list of students:
List students ;
The Student class has all getters and setters, toString, and equals+hashCode implemented.
We need to group all students by their course.
students.
.
..;
// 1=[Alex: Physics 1, Mike: Finance 1, Richard: History 1, Ann: Psychology 1]
// 2=[Julia: Biology 2, Hinata: Biology 2, Kate: Psychology 2]
// 3=[Maximilian: ComputerScience 3]
// 4=[Rika: Biology 4, Steve: History 4, Sergey: ComputerScience 4]
// 5=[Tim: ComputerScience 5]
Display a list of specialties in alphabetical order in which the students in the list are studying.
students.
.
.
.
.;
// Biology
// ComputerScience
// Finance
// History
// Physics
// Psychology
Display the number of students in each specialty.
students.
.
.;
// Psychology: 2
// Physics: 1
// ComputerScience: 3
// Finance: 1
// Biology: 3
// History: 2
Group students by specialty, maintaining the alphabetical order of specialties, and then group by course.
Map result ;
Now, display this nicely.
result.;
-= Biology =-
2: Hinata, Julia
4: Rika
-= ComputerScience =-
3: Maximilian
4: Sergey
5: Tim
-= Finance =-
1: Mike
-= History =-
1: Richard
4: Steve
-= Physics =-
1: Alex
-= Psychology =-
1: Ann
2: Kate
Check if there are any third-year students among all specialties except physics and computer science.
students.
.
.;
// false
Calculate the number Pi using the Monte Carlo method.
final Random rnd ;
final double r ;
final int max ;
long count ;
System.out.;
// 3.1415344
Display a multiplication table.
IntStream.
.
.
.;
// 2 * 2 = 4
// 2 * 3 = 6
// 2 * 4 = 8
// 2 * 5 = 10
// ...
// 9 * 7 = 63
// 9 * 8 = 72
// 9 * 9 = 81
Or a more exotic version, in 4 columns, like in school notebooks.
IntFunction function ;
IntFunction repeaterX ;
IntFunction repeaterY ;
IntFunction row ;
IntStream...;

But of course, this is a joke. No one is forcing you to write such code. 😬
12. Tasks#
IntStream.
.;
// 2, 3, 4, 5, -1, 0, 1, 2
IntStream.
.
.
.
.
.;
// !interactive answer='10', !interactive answer='11', !interactive answer='12', !interactive answer='13'
IntStream.
.
.
.
.;
// 5, 6, 7
IntStream.
.
.
.
.;
// 3, 4
IntStream.
.
.;
// 1, 2, 2, 3, 3, 3, 4, 4, 4, 4
int x ;
// x: 0
IntStream.
.
.
..;
// false=[1, 3, 5, 7, 9]
// true=[0, 2, 4, 6, 8]
IntStream.
.
./*!interactive size='7' answer='sorted'*/
.;
// -5, -4, -3, -2, -1, 1, 2, 3, 4, 5
IntStream.
.
./*!interactive size='5' answer='boxed'*/
.
.;
// -1, 1, -2, 2, -3, 3, -4, 4, -5, 5
IntStream.
.
.
.
..;
// 1=1
// 2=2
// 3=3
// 4=4
13. Tips and best practices#
-
If you can't solve a problem elegantly with streams, don't solve it with streams.
-
If you can't solve a problem elegantly with streams, don't solve it with streams!
-
If the problem is already elegantly solved without streams, everything works, and everyone is satisfied, don't rewrite it with streams!
-
In most cases, there's no need to store a stream to a variable. Use method chaining instead.
// Hard to read Stream stream ; stream ; stream.; // Better list. . .; -
Try to filter the stream of unnecessary elements or limit it first, and then perform transformations.
// Inefficient list. . . .; // Better list. . . .; -
Don't use parallel streams everywhere. The overhead of splitting elements, processing them in another thread, and then merging them can sometimes outweigh the benefits of single-threaded execution. Read more about it here: When to use parallel streams.
-
When using parallel streams, make sure there are no blocking operations or anything that could interfere with element processing.
list. . ... -
If somewhere in the model you return a copy of a list or another collection, consider replacing it with streams. For example:
// Before // After
Now you have the option to get not only a list model.dataStream().collect(toList());, but also a set, any other collection, filter something, sort, and so on. The original List<String> data remains untouched.